coroutine을 알기위해선 asynchronous process의 역사를 간략이 알아야할 필요가 있다. async process, 즉 비동기 처리는 예전부터 필요한 경우들이 있다. 예를 들어 네트워킹, DB 작업등은 응답에 시간이 걸리기 때문에, 메인쓰레드에서 처리하게되면 그동안 프로그램이 멈추게된다. 그래서 쓰레드를 이용한 처리방식이 일반적이다.
문제는 쓰레드라는 놈이 다루기 너무 까다롭다는데 있다. 일단, 별도의 context를 갖기 때문에, 쓰레드를 생성하는 일은 부하가 크게 걸리는 일이다. 쓰레드의 종료시점도 문제다. 쓰레드는 정확한 종료시점을 보장해주지 않는다. 즉, 쓰레드를 종료하고 다시 실행하고자 하는 경우 이전 쓰레드의 종료를 보장하지 않기 때문에 사용이 제한된다. 이를 해결하기 위해 쓰레드 내에서 코드적으로 관련된 부분을 구현해 사용해야 한다.
또한, 메인쓰레드와 시그널을 주고받거나 메세지를 주고받아야 하는 경우에는 직접 동기화 오브젝트를 사용하여 구현하거나 handler를 이용하여 관련 내용들을 구현해줘야 한다. 과거에는 이 모든걸 직접 구현해 사용했지만, 머리가 복잡해지는건 당연하다.
쓰레드의 생성시 걸리는 부하와 명확하지 않은 종료시점에 대한 좋은 해결책은 Thread Pool 방식이 있다. Thread Pool이란, 쓰레드들을 미리 만들어놓고, 쓰레드가 필요하면 생성해놓은 쓰레드를 작업에 할당했다가, 작업이 끝나면 다시 반환하는 방식이다. Coroutine에서도 기본적으로는 Thread Pool을 사용한다.
여러 어려움이 있지만, 어렵다고 쓰레드를 사용하지 않을수는 없다. 근본적으로는 쓰레드를 사용할 수 밖에 없기 때문에 쓰레드를 사용은 하되, 사용자가 간단하게 접근할 수 있게 만드는게 핵심이다. 이런 방법들이 점점 진화하며 여러가지가 나왔는데, 현재까지의 가장 진보적인 구현이 Kotlin의 coroutine으로 생각된다.
쓰레드부터 코루틴이 나오기까지 (Thread>Callback>Future, Promise>Coroutine) 진화과정은 다음 문서를 참조: Asnychronous programming techniques
코루틴은 매우 가벼운 소프트웨어적 쓰레드(light weight thread)라고 할 수 있다. 쓰레드에 익숙하다면, 코루틴을 그냥 쓰레드라고 생각해 버리는 것도 이해에 도움이 될 것이다. 물론 똑같지는 않고, 이해해야할 내용들이 더 있지만. 간단한 쓰레드부터 시작해보자.
fun main(args: Array<String>): Unit {
val thread = Thread {
for (i: Int in 1..100000) {
print("$i")
}
}
thread.start()
println("\nend of main")
}단순하게 많은 수의 반복을 하면서 숫자를 찍는 쓰레드를 람다 형태로 정의해 사용하고 있다. 쓰레드를 생성하고 메인 쓰레드는 바로 종료하고 있는데, 실행해보면 100000까지 다 찍고 쓰레드가 종료되는걸 볼 수 있다.
이와 동일한 형태로 코루틴으로 만들어보면 다음과 같다.
fun main(args: Array<String>): Unit = runBlocking {
launch {
for (i: Int in 1..100000) {
print("$i ")
}
}
println("\nend of main")
}우선, 메인함수에 runBlocking을 사용하고 있는데, 이는 블럭내의 코루틴이 완료될 때까지 블로킹 상태로 기다리도록 하는 코루틴 빌더의 하나이다. 앞에서 쓰레드는 쓰레드에 대한 통제권이 따로 없기 때문에 끝까지 실행됐는데, 코루틴은 메인 쓰레드가 종료되면 내부의 코루틴도 알 수 없는 영향을 받아 종료되어 버린다. 여러가지 테스트를 해봤는데, 이는 아마도 계획되지 않은 비정상 시나리오로 보인다. 이런식으로 사용하면 안되는거지. 코루틴은 필수적으로 CoroutineScope라고해서 언제까지 살아있어야 하는지 정해진 라이프 사이클을 갖는다. 안드로이드에서는 Activity를 따라갈 수도(LifecycleScope), Viewmodel의 lifecycle을 따라갈 수도(ViewmodelScope) 있다. 쓰레드도 마찬가지지만, 보통은 코루틴을 사용하는 유저가 종료됐는데 코루틴 혼자 돌고 있을 필요도 없고 오류를 발생시킬 수도 있기 때문이다. 안드로이드의 경우, Activity가 UI업데이트를 위해 코루틴을 사용하는데, Activity가 사라졌음에도 코루틴이 UI업데이트를 시도한다면 에러가 발생할테니까. 쓰레드는 이런 부분들ㅇ르 직접 구현해야 하는 사항이지만, 코루틴에서는 CoroutineScope로 만들어져 제공된다. 위 main함수에서는 명시적으로 CoroutineScope를 표시한 부분이 안보이는데, 특별한 경우로서 runBlocking이 바로 이에 해당한다. 이를 사용함으로써, main함수가 runBlocking내의 코루틴을 모두 실행 한 후, 종료되도록 만든다. 코루틴은 코틀린이 제공하는 언어적 기능이지, 안드로이드 특화된 기능이 아니다. 찾아보면 대부분 안드로이드 예제만 가득한데, runBlocking을 사용하면 간단한 코틀린 메인함수에서 코루틴들의 테스트가 얼마든지 가능해진다. 여기서는 이를 이용해서 기본적인 코루틴에 대한 설명을 하고, 안드로이드로 넘어가서 특화된 내용을 다룰 것이다.
말이 좀 길어졌는데 다시 코드로 돌아가자. runBlocking안에 launch가 사용되고 있는데, 이게 일반적으로 사용하는 코루틴 빌더이다. 이 내부의 코드는 쓰레드처럼 별도로 실행된다. 이름이 launch인 이유는 로켓처럼 쏘고 잊어버리는것(fire and forget)으로 바로 리턴되기 때문이다. 실행해보면, 메인 쓰레드가 먼저 끝나 “end of main”이 출력되고 코루틴 코드가 출력되는 걸 볼 수 있다. 앞에서 말했듯, runBlocking 때문에 코루틴이 모두 실행되고 끝난다.
Dispatcher
“코루틴은 쓰레드와 동일하게 작동하네?” 라고 생각할 수 있다. 앞에서 코루틴은 light thread라고 말했었다기 때문에 거의 동일한 방식으로 사용이 가능하다. 흥미로운건 하나의 쓰레드에서 여러개의 코루틴이 돌 수도 있다는 점이다. 마치, Unity 게임엔진의 coroutine과 비슷한 점인데, Unity는 단일 쓰레드로 돌기 때문에, Unity의 coroutine을 만들어주면 게임 루프상에서 매번 호출해주며 별도의 쓰레드가 도는듯한 착각을 불러일으킨다.
확인을 위해, 앞에서 돌린 코루틴의 쓰레드를 찍어보자.
fun main(args: Array<String>): Unit = runBlocking {
print(Thread.currentThread().name + Thread.currentThread().id + "\n")
launch {
print(Thread.currentThread().name + Thread.currentThread().id + "\n")
for (i: Int in 1..100000) {
print("$i ")
}
}
println("\nend of main")
}결과는 다음과 같이 보일 것이다.
main1
end of main
main1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ...둘 다 main1이 찍혔다. 같은 쓰레드란 얘기다. “end of main”이 먼저 찍혀서 별도의 쓰레드로 보인 것 뿐이다. 즉, launch를 실행하고 바로 리턴받아 “end of main”을 찍고, 다시 launch내의 코드를 실행한 것이다. 쓰레드의 이름을 찍듯이, 코루틴을 구별하는 고유한 값을 찍어볼 수도 있다. 다음의 코드를 실행해보자.
fun main(args: Array<String>): Unit = runBlocking {
print(Thread.currentThread().name + Thread.currentThread().id + "\n")
println("coroutine context : ${coroutineContext[Job]}" + "\n")
launch {
print(Thread.currentThread().name + Thread.currentThread().id + "\n")
println("coroutine context : ${coroutineContext[Job]}" + "\n")
for (i: Int in 1..100000) {
print("$i ")
}
}
println("\nend of main")
}coroutineContext에 대해선 뒤에서 다룰 것이니 일단 넘어가고, 실행 결과는 다음과 같다.
main1
coroutine context : BlockingCoroutine{Active}@b5b18566
end of main
main1
coroutine context : StandaloneCoroutine{Active}@5f90063코루틴 식별자는 runBlocking과 launch가 다른 것을 볼 수 있다.
코루틴은 하나의 쓰레드 안에서도 이와같이 여러개가 실행 가능하기 때문에, 코루틴이 실행될 쓰레드를 고를 수도 있다. 다음과같이 launch에 인자로 Dispatchers.Default를 넘겨보자.
...
launch(Dispatchers.Default) {
...결과를 보면,
main1
coroutine context : BlockingCoroutine{Active}@d8851b26
end of main
DefaultDispatcher-worker-130
coroutine context : StandaloneCoroutine{Active}@7aa9f6c5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ...쓰레드 이름이 달라진걸 볼 수 있다! 즉, launch에 인자로 코루틴이 실행될 쓰레드를 선택할 수 있다. 그런데, Dispatchers는 어디서 나온 것인가? 코틀린에서 코루틴 사용시, 쓰레드 풀을 이용하여 기본적인 몇개의 쓰레드를 생성해 놓는다. 생성되는 쓰레드들은 다음과 같다.
| Dispatchers.Main | 안드로이드에서만 쓰인다. UI 메인 쓰레드를 의미 |
| Dispatchers.Default | 별도의 쓰레드가 필요한 대부분의 것들을 위한 쓰레드 |
| Dispatchers.IO | 입출력은 시간이 많이 걸리는데, 이를 위한 쓰레드 |
| Dispatchers.Unconfined | 코루틴이 실행되는 순간마다, 자신을 호출한 쓰레드에서 실행된다. 매번 쓰레드가 바뀔 수 있다는 것. |
Dispatchers라는 이름을 갖는 것은, launch()가 실행할 코드를 해당 쓰레드로 dispatch(보내기, 발송)하기 때문이다. Unconfined가 잘 이해안될 수 있는데, 별로 쓸일은 없으며 공식 문서를 살펴보기 바란다.
당연하게도 직접 Custom Dispatcher를 만들어 사용할 수도 있지만, 사용할 일이 별로 없으므로 여기선 생략한다.
suspend function
그렇다면, 코루틴은 어떻게 하나의 쓰레드에서도 돌아가는걸까? 이 질문에 대한 답은, 코루틴은 중간에 멈추거나(Stop) 멈춘 부분부터 다시 실행(resume)할 수 있다는 것이다. 이런 stop-resume이 자동으로 이루어지는 것은 아니다. 쓰레드에도 프로세스를 독점하지 않기 위해 다른 쓰레드에게 양보하는 yield() 함수를 제공한다. 코루틴도 협력적인 관계를 통해 하나의 쓰레드를 공유하는데, 쓰레드의 sleep()에 해당하는 delay(), 쓰레드의 yield() 에 해당하는 yield()를 제공한다. 이들이 사용되면, 코루틴을 멈추고 같은 쓰레드를 사용하는 다른 코루틴에게 실행권을 넘겨준다. 다음 코드를 보자.
fun main(args: Array<String>): Unit = runBlocking {
launch {
for (i: Int in 1..100) {
println("printName01 : $i ")
}
}
launch {
for (i: Int in 1..100) {
println("printName02 : $i ")
}
}
println("\nend of main")
}메인 함수에서 하나의 메인 쓰레드로 두개의 코루틴을 실행하고 있다. 출력결과를 살펴보면,
end of main
printName01 : 1
printName01 : 2
printName01 : 3
printName01 : 4
...
printName01 : 98
printName01 : 99
printName01 : 100
printName02 : 1
printName02 : 2
printName02 : 3
...위와 같이 첫번째 코루틴이 모두 실행되고, 두번째 코루틴이 실행되어 끝난다. 보통 쓰레드처럼 쓰기위해 병렬 실행을 원한다면 기대한 결과가 아니다. 여기에 delay() 또는 yield()를 사용하면 원하는 결과를 얻을 수 있다.
fun main(args: Array<String>): Unit = runBlocking {
launch {
for (i: Int in 1..100) {
println("printName01 : $i ")
// delay(1)
yield()
}
}
launch {
for (i: Int in 1..100) {
println("printName02 : $i ")
// delay(1)
yield()
}
}
println("\nend of main")
}값 하나를 출력하고 yield()를 사용하고 있는데, 이 지점에서 멈추고 다른 코루틴에게 실행권을 넘겨준 다음, 다시 실행권을 받을 때, 여기서부터 계속 실행된다. delay()를 써도 비슷하지만, 여기엔 시간인자가 들어가므로 다른 시간값을 주면, 두 루프의 속도가 다른속도로 돌아가는 결과를 얻을 수 있다. 출력 결과는 다음과 같다.
end of main
printName01 : 1
printName02 : 1
printName01 : 2
printName02 : 2
printName01 : 3
printName02 : 3
...yield()를 사용해서 하나씩 순서를 바꿔가며 실행되는걸 볼 수 있다.
사실, delay()나 yield()를 보면, 함수 앞에 ‘suspend’ modifier가 붙어있다. 이걸 suspend function이라 부르는데, 이 함수들을 코루틴에서 사용하겠다는 표시이다. 실제로 suspend 함수들은 코루틴 또는 다른 suspend 함수 내에서만 사용가능하다. 사용자가 suspend를 만드는 경우, 컴파일러가 특별한 작업을 하진 않기 때문에 협력적으로 stop and resume이 가능하도록 코드를 작성해야 한다. 마찬가지로 라이브러리에서 suspend 함수로 제공되는 것들은 stop and resume이 잘 작동할 것이라는 추측을 가지고 사용하게 된다.
suspend 함수가 어떻게 stop과 resume을 할 수 있는지는 2017년 코틀린 컨퍼런스의 Deep Dive into Coroutines on JVM 이나, Google IO 2019의 Understand Kotlin Coroutines on Android 를 참고하기 바란다. 적당히 납득만 하고 넘어가고 싶다면, Kotlin에서 제공하는 Sequence의 사용방법과 유사하다고 생각하기 바란다.
코루틴이 stop and resume 외에 가지는 가장 큰 특징중 하나는 cancel이 가능하다는 점이다. 쓰레드에서는 기본적으로 이 기능을 제공하지 않는다. 위의 코드를 변형한 예제를 살펴보자.
fun main(args: Array<String>): Unit = runBlocking {
val job01 = launch {
for (i: Int in 1..100) {
println("printName01 : $i ")
// delay(1)
yield()
}
}
val job02 = launch {
for (i: Int in 1..100) {
println("printName02 : $i ")
// delay(1)
yield()
}
}
println("\nend of main")
delay(10)
job01.cancel()
job02.cancel()
}코드를 살펴보면, 코루틴을 job01, job02라는 변수에 할당했다. 상세한 부분은 coroutine context에서 다루겠지만, 이렇게 함으로써 코루틴을 컨트롤 할 수 있게된다. delay(10)으로 잠시 기다린 다음, 각각의 코루틴을 cancel()로 중지시켰다. 결과를 보면,
...
printName01 : 52
printName02 : 52
printName01 : 53
printName02 : 53
printName01 : 54
Process finished with exit code 0실행이 되던중에 cancel되서 중지된 것을 확인할 수 있다.
사실, 이렇게 cancel이 가능한 이유는 yield()라는 suspend function을 사용했기 때문이다. 코루틴은 자체적으로 cancel을 시키는 기능이 없고, 단지 Active 상태인지, Cancel상태인지, 상태만 유지한다. yield() 코드내에서 상태를 체크하고 cancel 예외(exception)을 발생시키는 것이다. 정리하자면, stop and resume과 마찬가지로 suspend 함수를 만들 때, cancellation이 가능하도록 만들어 줘야 한다는 것이다. yield()를 빼고 직접 cancellation을 체크하는 코드를 만들어 보자.
fun main(args: Array<String>): Unit = runBlocking {
val job01 = launch(Dispatchers.Default) {
var i: Int = 1
while (currentCoroutineContext().isActive) {
println("printName01 : $i ")
i++
}
}
println("\nend of main")
delay(10)
job01.cancel()
}코드를 살펴보면, 우선 코루틴을 Dispatchers.Default 쓰레드로 실행한다. 같은 메인 쓰레드로 돌리면, yield()나 delay()없이는 실행권을 넘겨주지 않기 때문에 테스트가 불가능하다. 다음에 for문을 while문으로 변경했다. 코루틴 내에선 currentCoroutineContext()없이 isActive 참조가 가능하지만, 이해를 돕기위해 넣어봤다. 이와같이 코루틴의 Active상태를 체크할 수 있다. Active가 아니라면, 무한반복을 끝내고 코루틴은 종료될 것이다.
또하나의 방법은 ensureActive()를 쓰는 것이다. 다음 코드를 보자.
fun main(args: Array<String>): Unit = runBlocking {
val job01 = launch(Dispatchers.Default) {
for (i: Int in 1..10000) {
println("printName01 : $i ")
ensureActive()
}
}
println("\nend of main")
delay(1)
job01.cancel()
}코드를 다시 while대신 for문을 사용했고, for문 내에서 ensureActive()를 호출해주고 있다. ensureActive()는 다음과 같이 CancellationException 예외를 던져주는 함수이다.
if (!isActive) {
throw CancellationException()
}ensureActive()의 장점은 예외를 던지기 때문에, 직접 isActive를 체크하지 않아도, 코드 어디에서든 사용 가능하다는 점이다. 이를 사용한 출력결과는 다음과 같다.
...
printName01 : 2217
printName01 : 2218
printName01 : 2219
Process finished with exit code 0실행중 cancellation이 잘 발생한 것을 볼 수 있다. 코루틴 cancellation에 대해 더 깊은 내용은 다음 글을 참고.
Coroutine Context
코루틴을 실행하는 launch()를 살펴보면 다음과 같다.
fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job첫번째 인자로, CoroutineContext를 사용하고 있다. 기본값으로는 비어있는 CoroutineContext를 사용하고. 앞에서 우리는 여기에다가 Dispatcher를 넘겨주기도 했었다. 이 정체는 무언일까?
각 코루틴은 어떤 Dispatcher에서 실행되는지등의 고유한 정보들이 존재하고, 필요한경우 그 정보들을 알 수 있어야 한다. 이러한 코루틴 요소(Element)들의 집합이 Coroutine Context이다. 기본적으로 제공되는 Coroutine Context의 요소에는 CoroutineName, CoroutineDispatcher, Job, CoroutineExceptionHandler 이 있다.
- CoroutineName : 사용자가 디버깅등에 사용하기 위해 할당하는 코루틴 이름
- CoroutineDispatcher : 어떤 쓰레드로 dispatch 해서 실행할지 정하는 것.
- Job : 코루틴의 상태정보를 담고있고, 이를 통해 코루틴의 cancel이 가능하다.
- CoroutineExceptionHandler : Catch로 잡아내지 않은 Exception을 처리하기 위한 핸들러
CoroutineContext의 정체는 사실 Key-Element쌍을 저장하는 인터페이스이다. Element는 CoroutineContext를 상속받는 인터페이스이기 때문에, CoroutineName, CoroutineDispatcher, Job, CoroutineExceptionHandler 각각이 Element이면서 모두 CoroutineContext로 다루질 수가 있다. 그래서 launch()에 CoroutineContext 인자에 Dispatcher를 넘겨줬던 것이다.
흥미로운 부분은 인터페이스에 plus, minusKey가 존재해서, 각 Element들을 더하기 빼기 조합으로 추가하고 뺄 수가 있다는 점이다. 그래서 다음과 같이 사용이 가능하다.
...
val job01 = launch(Dispatchers.Default + CoroutineName("test coroutine")) {
...launch()로 실행시, job은 자동으로 추가가 된다. 코루틴 내부에서 Context를 얻어와 출력하는 코드는 다음과 같이 쓸 수 있다. 각 요소는 Context에 맵처럼 Key-Element 조합으로 저장 되어 있으므로, Key를 인덱스로 사용하여 조회가 가능하다.
@OptIn(ExperimentalStdlibApi::class)
fun main(args: Array<String>): Unit = runBlocking {
val job01 = launch(Dispatchers.Default + CoroutineName("test coroutine")) {
println("${currentCoroutineContext()[Job]}")
println("${currentCoroutineContext()[CoroutineName]}")
println("${currentCoroutineContext()[CoroutineDispatcher]}")
for (i: Int in 1..10) {
println("printName01 : $i ")
ensureActive()
}
}
println("\nend of main")
}코드를 살펴보면, currentCoroutineContext()로 CoroutineContext를 가져오고 있으며, map과 같이 키를 이용하여 값들을 출력하고 있다. 키중에서 CoroutineDispatcher는 아직 정식사용 api가 아닌지, @OptIn(ExperimentalStdlibApi::class 를 메인함수 위에 달아줘야 사용이 가능하다. 출력 결과는 다음과 같다.
end of main
StandaloneCoroutine{Active}@4d98aafc
CoroutineName(test coroutine)
Dispatchers.Default
printName01 : 1
...각각 잘 출력되는걸 확인할 수 있다.
Coroutine Scope
CoroutineScope는 어쩌면 가장 먼저 다뤘어야 할 내용일 만큼 중요한건데, 안드로이드에서 더 명확하게 보이는 부분이라서 마지막으로 다룬다. 코루틴은 무조건 특정 Scope를 갖는다. 다르게 말하면, 코루틴을 사용하는 루틴이 종료되서 더이상 코루틴이 필요하지 않는상황에 코루틴이 돌아가는 일이 없도록 해놨다는 것이다. 동작은 간단한데, 코루틴의 Scope를 소유하는 객체가 종료되기전에 코루틴의 cancel()을 불러주도록 만든 것이다. 다음의 예제를 보자.
class MyScopeClass {
val myScope = CoroutineScope(Dispatchers.Default)
fun destroy() {
myScope.cancel()
}
...위 코드를 보면, 클래스 내에서 CoroutineScope()를 이용해 새로운 커스텀 Coroutine Scope를 만들어주고 있다. 그리고 클래스가 정리되는 destroy()에서 cancel()을 불러주어 코루틴을 종료시킨다. cancel()은 CoroutineScope의 extension function으로 정의 되어 있다.
위 코드를 이용하여 테스트 코드를 작성해보자.
fun main(args: Array<String>): Unit = runBlocking {
scopedPrintNums()
println("\nend of main")
}
class MyScopeClass {
val myScope = CoroutineScope(Dispatchers.Default)
fun destroy() {
myScope.cancel()
}
fun printLoop() {
myScope.launch {
for (i: Int in 1..10000) {
println("$i ")
ensureActive()
}
}
}
}
suspend fun scopedPrintNums() {
val scopeInstance = MyScopeClass()
scopeInstance.printLoop()
delay(10)
}위 코드의 흐름을 그려보면 다음과 같다.
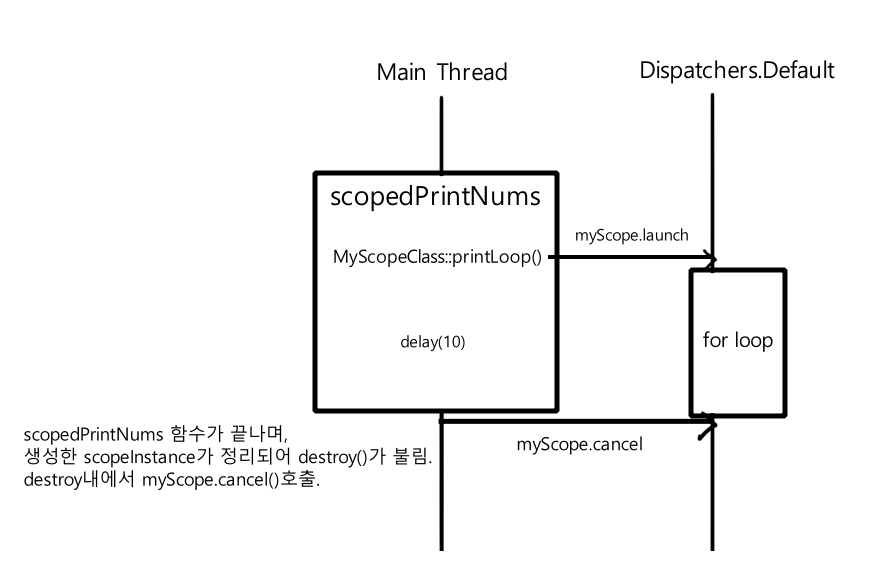
scopedPrintNums()함수가 호출되면, MyScopeClass의 인스턴스인 scopeInstance가 생성된다. 커스텀 코루틴 스코프인 myScope는 scopeInstance의 lifecycle과 함께하도록 destroy()에서 cancel()이 불리고 있다. printLoop()가 불리면, myScope.launch로 코루틴이 실행되고, myScope에 정의된 코루틴 컨텍스트대로, Dispatcher.Default의 쓰레드에서 for loop가 실행된다. scopedPrintNums()는 delay(10)으로 10ms 대기후에 함수가 종료된다. scopeInstance는 이 함수내에 정의된 인스턴스로 함께 종료되고 destroy가 불리며 myScope.cancel()이 불린다. myScope.cancel()에 의해 이 scope로 실행되던 코루틴의 for loop는 종료된다.
Android에서의 CoroutineScope
안드로이드에선 각 컴포넌트가 lifecycle을 갖고, 이에 따른 CoroutineScope를 제공한다. 바로 LifecycleScope와 viewModelScope이다. Activity나 Fragment들은 각각 자신의 LifeCycle을 갖고 있으며, 이렇게 Lifecycle을 갖는 경우 LifecycleScope를 사용할 수 있다. viewModel의 경우는 Activity나 Fragment가 종료되도 살아있기 때문에 별도의 viewModelScope를 갖는다.
class MyViewModel: ViewModel() {
init {
viewModelScope.launch {
// Coroutine that will be canceled when the ViewModel is cleared.
}
}
}ViewModel에서는 단순하게 viewModelScope를 사용할 수 있다.
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
...
lifecycleScope.launch { }
}
...Activity에서는 lifecycleScope를 사용하면 된다.
class MyFragment: Fragment() {
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
super.onViewCreated(view, savedInstanceState)
viewLifecycleOwner.lifecycleScope.launch {
val params = TextViewCompat.getTextMetricsParams(textView)
val precomputedText = withContext(Dispatchers.Default) {
PrecomputedTextCompat.create(longTextContent, params)
}
TextViewCompat.setPrecomputedText(textView, precomputedText)
}
}
}Fragment 에서는 viewLifecycleOwner.lifecycleScope를 사용하면 된다. Framgnet root 뷰의 Lifecycle owner로부터 lifecycleScope를 사용하는 것.
실제로 사용하다보면, Activity나 Fragment가 사용중에만 코루틴을 돌리고 싶을 것이다. UI 데이터를 코루틴으로 업데이트 하는데, Activity가 보여지지 않는다면 오버헤드일 뿐이니까. start()/stop()에서 사용자가 직접 코루틴을 실행하고 cancel()하는걸 넣어줄 수 있지만, LifecycleOwner의 repeatOnLifecycle()을 이용하면 단순하게 구현 가능하다.
viewLifecycleOwner.lifecycleScope.launch {
viewLifecycleOwner.repeatOnLifecycle(Lifecycle.State.STARTED) {
// Because collect is a suspend function, if you want to
// collect multiple flows in parallel, you need to do so in
// different coroutines.
launch {
flow1.collect { /* Process the value. */ }
}
launch {
flow2.collect { /* Process the value. */ }
}
}
}코드를 보면, repeatOnLifecycle()에 인자로 STARTED를 넘겨주고 있다. 이렇게 해주면, STARTED와 쌍을 맺는 STOPPED 상태가 되면 작동을 멈추고, 다시 STARTED가 되면 실행된다. 주의할 점은, repeatOnLifecycle()이 suspend 함수이므로, 코루틴 안에서 실행해야 한다는 점이다. 위 코드에서도 코루틴을 만들고 그 안에서 불러주고 있다.
Callback과 Coroutine
코루틴 자료를 찾아보면, 다들 callback형태의 문제점을 해결하기 위한 대체 방안으로 나온다. 이 포스팅에서는 쓰레드를 대체하는 관점으로 접근했는데, 나에게는 이런방식이 이해가 더 쉬웠기 때문이다. callback을 사용하는 경우는 long time job이 필요한 경우, 예를들면 네트워크에 접속하기위해 대기하거나, DB에 쓰는작업등에 사용하게 된다. 네트워크 작업을 하려면, 일단 연결이 완료 되어야 가능하니까, 연결된 뒤에 수행할 코드를 callback으로 넘겨주는 방식이다.
Google I/O 2019의 Understand Kotlin Coroutines on Android 세션 예제로 예를들어보자. 네트워크로 유저정보를 가져와 출력하는 경우, 콜백 스타일은 다음과 같다.
fun loadUser() {
api.fetchUser { user ->
show(user)
}
}fetchUser()가 별도의 쓰레드로 돌면서 작업이 완료되면, 넘겨준 람다 함수 형태의 콜백에서 show(user)가 UI 쓰레드에서 작업을 실행한다. ( 콜백을 불러주는건 쓰레드기 때문에, show(user) 도 쓰레드에서 실행된다. UI 메인쓰레드로 작업하기 위해선 show()내에서 handler등을 이용해야 한다.)
코루틴 방식을 살펴보자.
suspend fun loadUser() {
val user = api.fetchUser()
show(user)
}일단, 블럭킹 방식의 코드와 동일해서 사용하기 편해졌다. 실제로 콜백이 여러개 사용되는 경우, 무수한 들여쓰기를 동반한 최악의 형태를 보여주는데, 이를 callback hell이라고 한다. 코루틴 형태는 이를 피할 수 있다. 또한, 예외처리도 블럭킹 코드와 동일하게 처리해서 콜백 형태보다 진일보된 모습을 보여준다.
마무리 정리
코루틴을 모두 다루려니, 너무 내용이 많아진다. launch와 다른 async 도 있고, Dispatcher를 손쉽게 바꿔 사용하는 withContext도 있고, 안드로이드에서 사용하려면 livedata와 연계하는 방법이나 Flow를 또 알아야 하겠고… 일단, 내게 필요한 내용만 정리해서 여기서 마무리 짓겠다.
코루틴은 프로그래밍의 새로운 패러다임에 가까운 멋진 녀석이라 생각하는데, 소개된게 2017년 영상인거 보면 벌써 성숙한 부분이기도 하다. JAVA에서도 유사한 구현이 나올정도니까. 나야 겨우겨우 안드로이드 개발만 뒤늦게 따라가고 있긴한데, 전체적으로 패러다임이 객체지향에서 데이터의 흐름중심의 Reactive 방식으로 변화한다고 느낀다. 맞는 표현인지 모르겠지만 ㅋㅋ 마지막으로 참고할만한 자료를 몇개 드롭하면서 끝낸다.
- Kotlin의 coroutine은 공식문서를 참조.
- 안드로이드의 코루틴 가이드
- coroutine 내부구현에 대한 코멘트는 스택오버플로우
- 설명 영상은 MCE 2017 영상 참조.