Room에대해 정리하다가, DB의 실사용시 만나게 되는 one to one, one to many, many to many relationship을 어떻게 다루는지 별도로 정리하려고 이 글을 쓴다. SQL문과 Room을 비교해보면 이해가 쉽고 빠를거 같아서 그렇게 정리하려다가 android developer 블로그에 이미 정리된걸 발견했다. 아마도 여기서 크게 벗어나지 않을 것인데, 내용상 SQLite에서 사용하는 것만 먼저 정리해 올린다. Room을 이용하는건 별도 포스팅으로 올릴테니 원하는 내용은 그것까지 올려야 완성이다.
RDB에서 relationship은 가장 중요한 개념중 하나다. 데이터를 테이블 하나에 때려넣는게 아니라 RDB 이론에 따라 최적화된 테이블로 나눠서 저장하게 되는데, 이 테이블간의 관계가 relationship이다.
추상적으로 말했지만, 간단한 실제 예들은 얼마든지 들 수 있다. 간단한 택배관리 프로그램을 생각해보자. 특정 배송지로 보내지는 택배는 얼마든지 많을 수 있다. 하지만, 하나의 택배물품은 하나의 배송지 정보만 갖고있다. 이처럼 배송정보와 택배의 관계는 one to many의 관계가 된다. 주차권같은 티켓 관리 프로그램이라면, 자동차 또는 소유자와 티켓이 1:1 대응 된다. 이경우 one to one 관계이다. 블로그 글이나 인스타 포스팅에 해쉬태그를 다는 경우, 하나의 글에 여러개의 해쉬태그가 달릴 수 있고, 하나의 해쉬태그가 여러 글에도 달릴 수 있으므로 이경우는 many to many 관계가 된다.
one to one
앞에서 one to one relationship의 예로든 차와 주차권으로 DB 테이블을 그려보면 다음과같다.
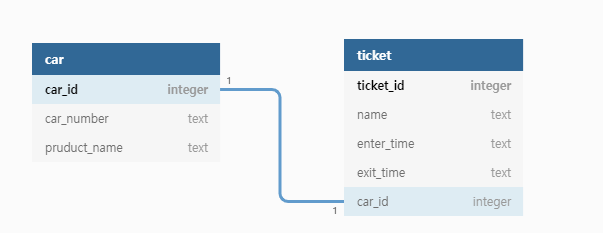
car는 ticket이 없을 수도 있지만, ticket은 꼭 하나의 차에 발급된다. 그래서 ticket에만 foreign key로 car_id를 갖고 있다.
이제 이걸 SQL로 적어보자. DB에 따라 조금씩 문법이 다른데, sqlite를 이용한다고 가정하겠다.
CREATE TABLE car (
car_id integer UNIQUE PRIMARY KEY,
car_number text NOT NULL,
pruduct_name text NOT NULL
);
CREATE TABLE ticket (
ticket_id integer UNIQUE PRIMARY KEY,
name text NOT NULL,
enter_time text,
exit_time text,
car_id integer UNIQUE,
FOREIGN KEY (car_id) REFERENCES car (car_id)
);FOREIGN KEY 부분을 주의깊게 보자. 이는 관계형 데이터베이스(RDB)에서 제약(Constraint)라고 불리는 것으로 참조무결성을 지키기 위해 참조값이 해당 테이블에 존재하지 않는경우 에러를 발생시킨다. 여기서는 다루지 않지만, 참조값이 지워지거나 변경되는 경우에는 원하는 동작을 하도록 할수도 있다. 추가로 볼만한 참조 링크를 남겨둔다.
SQL로 INSERT 및 QUERY를 해보자. 두개의 테이블에서 가져오기 때문에 JOIN을 이용한다.
INSERT INTO car (car_id, car_number, pruduct_name) VALUES (1, '11가1234', 'avante');
INSERT INTO car (car_id, car_number, pruduct_name) VALUES (2, '22너2345', 'damas');
INSERT INTO car (car_id, car_number, pruduct_name) VALUES (3, '33다3456', 'bmw m2');
INSERT INTO ticket (ticket_id, name, enter_time, car_id) VALUES (1, 'parking 1', '2021-01-03 09:30:00', 2);
INSERT INTO ticket (ticket_id, name, enter_time, car_id) VALUES (2, 'parking 1', '2021-02-10 13:10:00', 3);
SELECT car_number, pruduct_name, ticket.name as ticket_name, enter_time, exit_time from ticket INNER JOIN car ON ticket.car_id = car.car_id;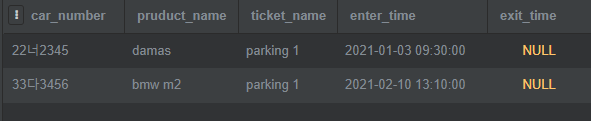
car 테이블에 샘플 데이터를 3개 넣고, ticket 테이블에 외래키로 car를 참조하는 샘플 데이터를 2개 넣었다.
SELECT로 값을 가져올 때는 필요한 필드만 표시했다. 두 테이블의 필드명이 동일한 경우, table.field 로 구별하고 ‘AS’ 를 이용해서 새 이름을 부여할 수 있다. 여기서는 name 필드가 무엇의 이름인지 명확하지 않으므로, ticket.name AS ticket_name 과 같이 이름을 변경해줬다.
SELECT의 대상 테이블은 FOREIGN KEY를 갖고 있는 ticket 테이블이 된다. INNER JOIN을 이용해 car 테이블과 병합시키는데, 외래키인 ticket.car_id = car.car_id 의 조건을 이용하고 있다.
- 오류 정정 : 위 코드에서 car table의 첫번째 아이템은 대응하는 티켓이 없다. 정확히 말해, 위 관계는 대응하는 티켓이 없을 수 있다는 얘기니까 1:1 이 아니라, 1:N 관계로 처리되어야 한다. 1:1 관계는 대응하는 아이템이 꼭 하나씩 있어야 한다.
one to many
앞에서 one to many의 예로든 택배 물품(package)와 배송정보(recipient)로 DB 테이블을 그려보면 다음과 같다.
- recipient를 receipient로 전부 잘못적었다. 텍스트는 다 고쳤는데, 이미지를 수정못함 ㅜ
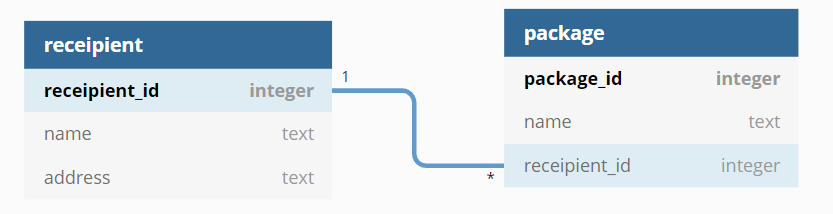
앞에서와 같이 SQL로 만들어보자.
CREATE TABLE 'recipient' (
'recipient_id' integer UNIQUE PRIMARY KEY AUTOINCREMENT,
'name' text not NULL,
'address' text not NULL
);
CREATE TABLE 'package' (
'package_id' integer unique PRIMARY key AUTOINCREMENT,
'name' text,
'recipient_id' integer,
FOREIGN KEY ('recipient_id') references 'recipient' ('recipient_id')
);one to one 에서 foreign key를 unique로 설정 안한걸 제외하고는 테이블 생성에선 차이점이 없다. 앞에선 빼먹었었는데, id 값들에 AUTOINCREMENT를 사용했다. insert시에 별도로 id를 넣어주지 않아도 자동으로 값이 증가하며 할당될 것이다. 여기서도 값을 넣고 가져와보자. 단, foreign key로 id값을 입력해야 하므로 테스트를 위해 AUTOINCREMENT에 맡기지 않고 id값을 직접 할당했다.
insert into recipient (recipient_id, name, address) values (1, '김택배', '서울시 짬뽕동 11-22');
insert into recipient (recipient_id, name, address) values (2, '포장지', '부산시 짬짜동 33-44');
insert into recipient (recipient_id, name, address) values (3, '강벽돌', '대전시 사기동 55-7');
insert into package (name, recipient_id) VALUES ('햇반 한상자', 1);
insert into package (name, recipient_id) VALUES ('컵라면박스', 1);
insert into package (name, recipient_id) VALUES ('커피포트', 1);
insert into package (name, recipient_id) VALUES ('박스티', 2);
insert into package (name, recipient_id) VALUES ('양말', 2);
insert into package (name, recipient_id) VALUES ('아이폰', 3);
insert into package (name, recipient_id) VALUES ('아이팟', 3);
select package.name as package_name, recipient.name as recipient_name, recipient.address from package INNER JOIN recipient on package.recipient_id = recipient.recipient_id;one to one과 크게 다르지 않다. 쿼리방법도 같은데 단지, 쿼리 결과가 one to many 형태일 뿐이다.
many to many
앞에서 many to many의 예로는 블로그 포스팅과 해쉬태그를 들었었다. 비슷하게 해쉬태그를 이용한 북마크 관리자를 만든다고 생각해보자. 해쉬태그는 특성상 어디에 붙든 many to many relationship이 될 것이다.
다이어그램으로는 테이블 두개로 직접 many to many표시를 할 수도 있지만, 실제 테이블 구성은 one to many로 두 테이블을 연결하는 junction(혹은 Bridge) 테이블을 사용하는게 정석이다. 이걸로 DB테이블을 그려보면 다음과 같다.
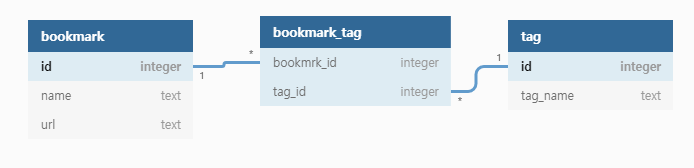
one to one, one to many를 다뤘기 때문에 테이블 3개를 쓴다는 것만 알게되면 이후는 어렵지 않다. 문제는 쿼리가 두번 필요하고, 두 쿼리의 결과를 합쳐야 한다는 것이다. 일단, 테이블을 만들어보자.
Create Table bookmark (
id integer UNIQUE PRIMARY KEY AUTOINCREMENT,
name text,
url text not NULL
);
create table tag (
id integer UNIQUE PRIMARY KEY AUTOINCREMENT,
tag_name text
);
create table bookmark_tag (
bookmark_id integer not NULL,
tag_id integer not NULL,
primary key(bookmark_id, tag_id),
FOREIGN KEY (bookmark_id) REFERENCES bookmark (id),
FOREIGN KEY (tag_id) REFERENCES tag (id)
);bookmark_tag 테이블은 bookmark_id, tag_id 로 이루어진 composite key를 primary key로 갖도록 했다. 각각 또한, FOREIGN KEY로 각 bookmark, tag 테이블을 참조한다.
이제 값을 입력하고 가져와보자.
insert INTO bookmark (id, name, url) VALUES (1, 'android developer', 'https://developer.android.com/');
insert INTO bookmark (id, name, url) VALUES (2, 'unity', 'https://unity.com/');
insert INTO bookmark (id, name, url) VALUES (3, 'kotlin', 'https://kotlinlang.org/');
insert into tag (id, tag_name) VALUES (1, 'programming');
insert into tag (id, tag_name) VALUES (2, 'android');
insert into tag (id, tag_name) VALUES (3, 'unity');
insert into tag (id, tag_name) VALUES (4, 'game');
insert into tag (id, tag_name) VALUES (5, 'kotlin');
insert into tag (id, tag_name) VALUES (6, 'language');
insert into bookmark_tag (bookmark_id, tag_id) values (1, 1);
insert into bookmark_tag (bookmark_id, tag_id) values (1, 2);
insert into bookmark_tag (bookmark_id, tag_id) values (2, 1);
insert into bookmark_tag (bookmark_id, tag_id) values (2, 3);
insert into bookmark_tag (bookmark_id, tag_id) values (2, 4);
insert into bookmark_tag (bookmark_id, tag_id) values (3, 1);
insert into bookmark_tag (bookmark_id, tag_id) values (3, 5);
insert into bookmark_tag (bookmark_id, tag_id) values (3, 6);3개의 북마크를 만들고, 각 북마크당 몇개의 태그를 지정했다. 북마크와 태그는 별도의 테이블에 저장되지만, junction 테이블인 bookmark_tag 에 매칭정보가 저장된다.
앞에서는 단순하게 전체 테이블을 쿼리했다. 여기선 조금 자세히 선택적으로 해보자. 먼저, kotlin 사이트 북마크의 태그를 가져와보자.
SELECT bookmark.name, bookmark.url, tag.tag_name FROM bookmark_tag
INNER JOIN bookmark ON bookmark_tag.bookmark_id = bookmark.id
INNER JOIN tag ON bookmark_tag.tag_id = tag.id WHERE bookmark.name = 'kotlin'; 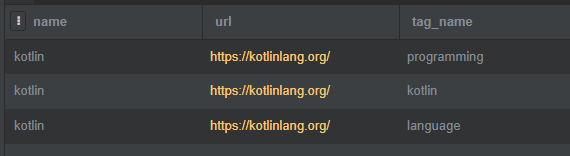
쿼리가 두번 필요하다고 했는데, SQL문에서 INNER JOIN이 두번 사용되고 있다. JOIN을 하면 새로운 테이블이 생기는 것과 마찬가지 이므로, 연쇄적으로 JOIN연산을 한다고 생각하면 되겠다. 여기에선 bookmar_tag와 bookmark를 먼저 JOIN하고 그 결과물을 tag와 JOIN한다고 이해하자. 내부 구현은 각 RDBMS마다 다르겠지만, 간단하게는 이정도면 충분할 거 같다. 이렇게 만들어진 테이블에서 WHERE 조건으로 bookmark의 이름으로 ‘kotlin’만 검색한 결과가 위와 같다. 이렇게 특정 북마크에 붙어있는 모든 태그를 가져올 수 있다.
이번엔 ‘programming’ 태그로 검색을 해보자. 예제를 조금 잘못만들어서 공통 태그가 이거 하나밖에 없다 ㅋ
SELECT bookmark.name, bookmark.url, tag.tag_name FROM bookmark_tag
INNER JOIN tag ON bookmark_tag.tag_id = tag.id
INNER JOIN bookmark ON bookmark_tag.bookmark_id = bookmark.id
WHERE tag_name = 'programming';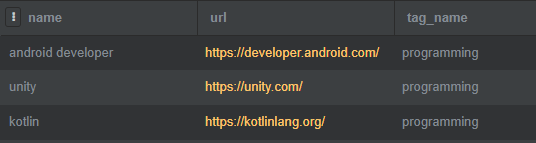
역시 두번의 INNER JOIN을 했다. JOIN의 순서를 바꿔봤는데, 여기에선 별 의미없고 동일한 결과가 나온다. WHERE 조건에 tag_name으로 ‘programming’을 필터링한 결과물이 위의 이미지이다. 이와같이 특정 해쉬태그에 해당하는 북마크들을 가져올 수 있다.
정리 및 그 다음단계
이렇게 one to one, one to many, many to many relationship을 sqlite에서 살펴봤다. relationship은 FOREIGN KEY로 명시를 했고 값을 가져올 땐 INNER JOIN으로 테이블을 합쳐 가져왔다. 복잡해 보이는 many to many 관계는 Junction table을 추가로 생성해서 3개의 테이블고 구성하고 두번의 INNER JOIN을 통해 값을 가져왔다.
Room을 사용하기전에, 좀 더 raw한 SQL레벨에서의 이해가 도움이 될거라고 생각해서 먼저 정리했다. 원래 목적은 안드로이드에서 Room을 사용하는 것이므로, 다음 포스팅에선 위와 동일한 내용을 Room으로 어떻게 다룰지 알아보려한다.
1 thought on “DB relationship with SQLite”