네트워크에서 데이터를 읽어오든지, DB에 저장된걸 가져오든지 데이터가 매우 많아지면 한번에 읽어올 때 문제가 생기게된다. 그렇다고 화면에 보이는 만큼만 매번 읽어오게되면, 스크롤등을 이용하여 데이터를 살펴볼 때, 렉이 생길 것이다. 이를 해결하기위해 사용자 입력에 충분히 반응할만큼 여유있는 데이터를 읽어오고, 사용자가 추가적으로 데이터를 살펴볼 때, 필요한 만큼씩 미리 읽어오는 기법이 오래전부터 사용되어 왔다. 이걸 paging 기법이라 하는데, 꼭 이런경우가 아니라도 여러곳에서 찾아볼 수 있다.
가장 가까이에서 찾아볼 수 있는 곳은 Operating System이다. OS에서 paging 기법은 메모리를 확장하는데 사용된다. 고정된 데이터 사이즈를 page라고 하며, HDD같은곳에 실제보다 훨씬 큰 가상메모리를 만들어놓고 사용하는 page들만 실제 메모리에 올려서 쓰는 방식이다.
Database에서도 찾아볼 수 있다. 데이터가 많은 경우, 쿼리 결과를 모두 메모리에 올릴 수 없거나 부담스러울 수 있다. 이 경우, Database 자체에서 필요한 만큼씩만 page단위로 메모리로 읽어와 사용하는 방식이 구현되기도 한다.
Android에서는 SQLite에서 쿼리를 사용할 때 ‘limit’문을 이용하거나 직접 구현해서 써오다가, Android Jetpack의 일부로 이를 지원하는 Paging library가 나오게 되었다. 현재는 Paging 3 까지 나와있고, Room에서도 이를 지원한다.
SQLite의 Paging
안드로이드에서 SQLite의 SQLiteCursor를 이용한 paging의 경우 발생가능한 여러 문제점들을 안드로이드 개발 공식 블로그 글 에서 지적하고있다. 2017년도 글이고 현재는 개선이 많이되서 이와 같지는 않다고 하지만 여전히 도움이 되는 내용으로 보인다. 이 글의 내용을 조금 살펴보겠다.
SQLite를 직접 사용하는 경우를 살펴보면, 쿼리를 날렸을 때 결과값의 데이터가 많은경우 전체를 메모리에 올릴 수 없기 때문에 CursorWindow라는걸 이용한다. 현재 사용중인 CursorWindow를 메모리에 올리고 사용하다가 참조하는 데이터가 CursorWindow에 없을 때, 새로 refresh되는 식이다. 우리가 쿼리에서 리턴받는 SQLiteCursor는 이 메모리상의 CursorWindow의 한 부분을 가리키게 된다. 이것은 앞서 얘기한 Paging 기법에 해당하는데, CursorWindow가 고정된 크기의 page에 해당한다.
이에대해 몇가지 문제점들이 나열되어 있는데, 대충 살펴보면 CursorWindow가 refresh될 때, 마치 링크드 리스트의 데이터를 가져오는 것처럼, 매번 처음부터 읽으면서 원하는 CursorWindow의 위치까지 DB의 row들을 스킵하게 되어있다고 한다. SQLiteCursor가 query를 resume하는 기능이 없어서라고 하는데, 데이터가 많을수록 시간이 많이 소모될 것이다. 이는 SQLiteCursor.getCount()를 부를 때에도 유사하게 전체 리스트가 스캔된다고 한다.
또다른 문제로, 사용한 Cursor는 close()가 되어야 한다. 이는 전적으로 개발자에게 달려있는 책임이다. 또한, SQLiteCursor는 사용중 데이터의 변경에 대해 알지 못한다. 다른건 무시하고 사용한다고 해도, 이건 좀 문제가 될 수 있다.
이러한 문제들의 workarround 해결책으로 제시되는게 small queries이다. CursorWindow하나로 처리될만한 양만큼씩 쿼리를 하게되면 문제가 없다는 것. Room을 매우 선호하는 이유가 이것이라고 하니, Room의 자세한 구현내용은 모르겠지만, 이런 부분들이 고려가되어 있다고 보인다. small query의 단점은 명확한데, CursorWindow하나만 사용하기 때문에 paging의 기능을 제대로 발휘하지 못한다는 것이다. 데이터가 많아지면, query의 수가 많아지는 거니까. 그래서 권장하는게 직접 컨트롤 가능한 Paging Library + Room 의 조합이다.
Android Jetpack: Paging Library
안드로이드 paging library는 version 2를 지나 3까지 왔다. 공식 가이드문서를 당연히 보는게 좋다. 여기서는 이 공식 가이드 문서를 중심으로 정리해볼 생각이다. 많은 데이터를 화면에 뿌리는 경우, RecyclerView를 사용할텐데, 이 라이브러리를 사용하면 이를 위한 Adapter도 제공한다.
먼저, 라이브러리 사용을 위해 gradle파일에 추가가 필요하다. 라이브러리 정보는 Jetpack의 해당 라이브러리 페이지를 참조하자.
dependencies {
def paging_version = "3.0.0"
implementation "androidx.paging:paging-runtime:$paging_version"
// alternatively - without Android dependencies for tests
testImplementation "androidx.paging:paging-common:$paging_version"
라이브러리 기본구조
paging 라이브러리는 android app architecture에 맞춰져있다. 이에 따라, Repository, ViewModel, UI 의 세개 레이어별로 들어가는 라이브러리 컴포넌트가 존재한다.
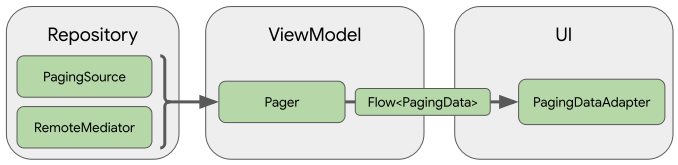
1. Repository Layer
Repository에서는 다양한 데이터소스에 따라 데이터를 제공한다. Paging 라이브러리에는 이에 해당하는 PagingSource 클래스를 제공하니 바로 사용하거나 상속받아 사용이 가능하다. Room을 사용하는 경우, @Query 어노테이션에 리턴값으로 PagingSource를 지원하고 있어 Room과 연동되는 경우에 간단히 사용가능해진다.
RemoteMediator는 네트웍의 데이터를 읽어오는 모듈이다. 네트워크에서 데이터를 읽어오는 경우, DB를 Cache로 생각해서 DB에 저장하고 PagingSource를 통해 DB에 저장한 데이터를 제공하도록 가이드하고 있다. 이것은 Single source of truth라고 하는 가이드인데, 데이터 소스가 네트워크와 DB 두가지가 되는경우, 서로 다른 데이터를 가지고 있을 수 있기 때문에 단일한 데이터를 제공하기 위함이다. RemoteMediator는 아직 experiment api로 변경 가능성이 있다.
2. ViewModel Layer
ViewModel Layer에서는 실제로 UI에 보여질 데이터를 제공해야한다. Repository로부터 데이터를 가져와 제공하는 라이브러리 모듈로 Pager 클래스를 제공하고 있다. Pager 클래스는 PagingConfig를 인자로 받는데, PagingConfig는 page size나 기타 설정정보를 포함하게된다.
Pager는 최종적으로 Flow<PagingData>를 제공한다. PagingData는 역시 라이브러리에서 제공하는 클래스로 실제 한 page에 해당하는 데이터를 담고 있다.
3. UI Layer
UI 레이어에서는 ViewModel에 있는 Flow<PagingData>를 직접 활용할 수도 있으며, RecyclerView를 위한 PagingDataAdapter를 제공하니 이를 상속받아 구현할 수 있다.

Paging Library 구현 예
이제 실제로 구현을 해보자. RemoteMediator는 일을 복잡하게 만들기 때문에 일단 배제하고 시작하자. 앞서 기본구조에서 봤겠지만, PagingSource, Pager, PagingDataAdapter의 구현이 핵심이다.
어떻게 구현하는지 기본적인 설명은 공식 가이드문서에 있다. 하지만, 직접 구현하는데 처음 보고 따라하기는 쉽지 않기 때문에 제공되는 샘플코드 참조하거나, 코드랩의 Android Paging을 보는게 도움이된다. 샘플코드는 database만 이용하는 것과 네트워크에서 데이터를 읽어오는 경우 두가지가 있다.
가장 쉽게 읽히는 database를 이용하는 샘플코드를 살펴보도록 하자. 앞에서 말했듯이, PagingSource, Pager, PagingDataAdapter의 구현을 봐야한다. 그런데, 샘플코드와 같이 Room을 이용하는 경우, Paging을 직접 지원하여 리턴값으로 PagingSource를 지원한다. CheeseDao를 살펴보면, 아래와 같은 코드를 볼 수 있다.
@Dao
interface CheeseDao {
/**
* Room knows how to return a LivePagedListProvider, from which we can get a LiveData and serve
* it back to UI via ViewModel.
*/
@Query("SELECT * FROM Cheese ORDER BY name COLLATE NOCASE ASC")
fun allCheesesByName(): PagingSource<Int, Cheese>
...쿼리의 리턴값으로 PagingSource를 사용하고 있는데, PagingSource를 직접 구현하지 않고, Room에서 처리해주게 된다.
PagingSource<Key, Value>와 같이, Key, Value의 두 generic 타입을 받는다. Key가 page number에 해당하는 값이고, Value는 다루는 데이터에 해당한다. 앞의 코드에서는 Key로 Int, Value로 Cheese가 사용되는걸 볼 수 있다.
PagingSource가 준비됐으면, 필요할 때 PagingSource로부터 데이터를 로드하는 Pager를 구현해야 한다. Pager는 ViewModel안에서 구현된다. 예제의 CheeseViewModel을 살펴보자.
val allCheeses: Flow<PagingData<CheeseListItem>> = Pager(
config = PagingConfig(
/**
* A good page size is a value that fills at least a few screens worth of content on a
* large device so the User is unlikely to see a null item.
* You can play with this constant to observe the paging behavior.
*
* It's possible to vary this with list device size, but often unnecessary, unless a
* user scrolling on a large device is expected to scroll through items more quickly
* than a small device, such as when the large device uses a grid layout of items.
*/
pageSize = 60,
/**
* If placeholders are enabled, PagedList will report the full size but some items might
* be null in onBind method (PagedListAdapter triggers a rebind when data is loaded).
*
* If placeholders are disabled, onBind will never receive null but as more pages are
* loaded, the scrollbars will jitter as new pages are loaded. You should probably
* disable scrollbars if you disable placeholders.
*/
enablePlaceholders = true,
/**
* Maximum number of items a PagedList should hold in memory at once.
*
* This number triggers the PagedList to start dropping distant pages as more are loaded.
*/
maxSize = 200
)
) {
dao.allCheesesByName()
}.flow
.map { pagingData ->
pagingData
// Map cheeses to common UI model.
.map { cheese -> CheeseListItem.Item(cheese) }
.insertSeparators { before: CheeseListItem?, after: CheeseListItem? ->
if (before == null && after == null) {
// List is empty after fully loaded; return null to skip adding separator.
null
} else if (after == null) {
// Footer; return null here to skip adding a footer.
null
} else if (before == null) {
// Header
CheeseListItem.Separator(after.name.first())
} else if (!before.name.first().equals(after.name.first(), ignoreCase = true)){
// Between two items that start with different letters.
CheeseListItem.Separator(after.name.first())
} else {
// Between two items that start with the same letter.
null
}
}
}
.cachedIn(viewModelScope)Pager의 생성과 동시에 flow 속성을 참조하고 있다. 우선, 생성자에 PagingConfig가 보인다. PagingConfig는 몇가지 Paging 값들을 지정해주는데, pageSize는 한번에 읽어올 아이템 개수를 말한다. enablePlaceHolder는 로딩시, 데이터가 아직 없을 때 null상태의 placeholder를 사용하는지 여부이다. maxSize는 PagingData의 최대 크기를 말한다. 데이터를 읽어올 때 pageSize만큼씩 읽어와서 PagingData에 쌓이게되는데, 지정한 최대크기보다 커지면 데이터를 메모리에서 드롭시킨다. 예제에서 200으로 지정되어 있으므로, 60씩 4번의 로딩이 일어나면 아마도 데이터의 drop이 발생할 것이다. 이값을 MAX_SIZE_UNBOUNDED로 설정하면 drop없이 계속 쌓이게된다. maxSize에 대한 보다 자세한 내용은 공식 레퍼런스를 참고하자.
Pager의 레퍼런스를 보면 생성자의 정의는 다음과 같다.
<Key : Any, Value : Any> Pager(
config: PagingConfig,
initialKey: Key?,
pagingSourceFactory: () -> PagingSource<Key, Value>
)
<Key : Any, Value : Any> Pager(
config: PagingConfig,
initialKey: Key?,
remoteMediator: RemoteMediator<Key, Value>?,
pagingSourceFactory: () -> PagingSource<Key, Value>
)두가지 생성자가 있는데, RemoteMediator의 사용 유무 차이가 있다. 생성자를 보면, pagingSouceFactory로 lambda 표현식이 들어가게 되어있는데, lambda의 리턴값은 PagingSouce이다. 예제에선 lambda표현식에 dao.allCheeseByName()을 사용하여, Room에서 리턴되는 PagingSouce를 리턴하게 구현되었다.
Pager를 생성한 후에는 바로 연결해서 flow 속성을 사용하여 값을 변환해주고 있다. 값의 변환과정을 살펴보면,
.map{ cheese -> CheeseListItem.Item(cheese) }map을 이용해서 PagingData<cheese> 를 PagingData<CheeseListItem.Item(cheese)>로 바꿔준다. CheeseListItem을 살펴보면 다음과 같은데,
sealed class CheeseListItem(val name: String) {
data class Item(val cheese: Cheese) : CheeseListItem(cheese.name)
data class Separator(private val letter: Char) : CheeseListItem(letter.toUpperCase().toString())
}sealed class를 상속받아 data class를 만들면, enum을 대체해서 사용할 수 있다. 이에 관해서는 이전 포스팅, Sealed class vs Enum을 참조. 이걸 사용하는 이유가 바로 나오는데, 다음줄을 보면, insertSeparators()를 사용해서 알파벳 헤더모양의 separator를 추가하고 있다. 바로 recyclerview에 일반 아이템과 separator를 같이 표시하기 위함이다.
마지막으로,
...
.cachedIn(viewModelScope)위와 같이 cachedIn() 을 불러준다. 이 함수의 역할은 PagingData를 인자로 받은 scope내에서 Flow 데이터를 cach에 저장한다. 그러니까 위와같이 viewModelScope로 지정하면, Flow를 참조하는 Activity가 화면 로테이션에 의해 destroy 됐다가 다시 create되도 ViewModel에 데이터가 유지된다는 얘기다. 또 한가지 역할은 여러곳에서 데이터를 필요로 할 때, 쉐어가 가능하도록 만들어준다.
이렇게해서 ViewModel에 Flow<PagingData<CheeseListItem>>이 준비되었다. 다만, Flow는 Channel과 대비해서 cold stream이라고 말한다. 이 의미는 sequence와 마찬가지로 사용자가 직접 collect()를 호출할 때, 데이터를 가져온다. Flow를 생성했다고 불필요한 일이 일어나지 않는 것이다. 그러므로 이를 작동시키기 위해서 UI 레이어에서 collectLatest()를 불러준다. collectLatest()가 collect()와 다른점은, 새로운 값이 emit() 되면 진행하던 collectLatest() 블럭을 cancel하고 다시 처음부터 실행된다. Kotlin의 collectLatest() 문서를 보면 간단한 예제가 있으니 이해가 될 것이다.
UI 레이어에서 먼저 CheeseAdapter 클래스를 살펴보자.
class CheeseAdapter : PagingDataAdapter<CheeseListItem, CheeseViewHolder>(diffCallback) {
...Paging Library에서 제공하는 RecyclerView용 adapter인 PagingDataAdapter를 상속받아 구현하고 있다. PagingDataAdapter는 generic 인자로 recyclerview에서 사용할 아이템과 viewholer를 받는다. 추가로 diffCallback을 인자로 받고 있는데, 추가되는 아이템을 기존 아이템과 비교해서 실제로 UI에 추가할 데이터를 구분하는 역할을 한다. diffCallback이 어떻게 구현되어 있는지 살펴보자.
companion object {
/**
* This diff callback informs the PagedListAdapter how to compute list differences when new
* PagedLists arrive.
*
* When you add a Cheese with the 'Add' button, the PagedListAdapter uses diffCallback to
* detect there's only a single item difference from before, so it only needs to animate and
* rebind a single view.
*
* @see DiffUtil
*/
val diffCallback = object : DiffUtil.ItemCallback<CheeseListItem>() {
override fun areItemsTheSame(oldItem: CheeseListItem, newItem: CheeseListItem): Boolean {
return if (oldItem is CheeseListItem.Item && newItem is CheeseListItem.Item) {
oldItem.cheese.id == newItem.cheese.id
} else if (oldItem is CheeseListItem.Separator && newItem is CheeseListItem.Separator) {
oldItem.name == newItem.name
} else {
oldItem == newItem
}
}
/**
* Note that in kotlin, == checking on data classes compares all contents, but in Java,
* typically you'll implement Object#equals, and use it to compare object contents.
*/
override fun areContentsTheSame(oldItem: CheeseListItem, newItem: CheeseListItem): Boolean {
return oldItem == newItem
}
}
}DiffUtil.ItemCallback을 이용하여 areItemsTheSame(), areContentsTheSame() 두 메소드를 오버라이드해서 구현해주고 있다. 내용은 크게 어려울게 없을거라 생각된다.
준비는 모두 끝났고, 이제 adapter와 viewmodel에 Pager를 이용해 준비된 Flow를 연결하기만 하면 된다. MainActivity를 살펴보자.
// Subscribe the adapter to the ViewModel, so the items in the adapter are refreshed
// when the list changes
lifecycleScope.launch {
viewModel.allCheeses.collectLatest { adapter.submitData(it) }
}코루틴을 생성해서 실행하는데, viewmodel에 준비된 flow에 collectLatest로 값을 가져온다. 이렇게 가져온 PagingData<CheeseListItem>을 adapter.submitData()를 이용해 adapter로 보내준다. 주의할점은 PagingDataAdapter.submitData가 suspend fun 이라는 점이다. 일회성으로 종료되지 않고, 대기상태가 되기 때문에, 값이 변경되는 경우 collectLatest의 특성에 따라 다시 실행이 된다. 그러므로, 이 한줄로 데이터에 대한 observing 상태에 들어가서 지속적인 변경에 대해 값을 읽어오게된다.
Custom PagingSource 의 구현
앞의 예에선 PagingSource를 Room에서 제공하는걸 사용했다. DB만 사용시 이것으로 충분하겠지만, 사용자가 정의하는 경우도 알아보자. 예제로는 구글 코드랩 Android Paging 의 예를 살펴보자.
구글 코드랩 Android Paging 을 5단계까지 진행하면 GithubPagingSource를 만드는 부분이 있다. 해당 소스를 얻는 방법은 그 코드랩 2단계에 설명이 나와있다. 그럼 GithubPagingSource의 코드를 살펴보자.
private const val GITHUB_STARTING_PAGE_INDEX = 1
class GithubPagingSource(
private val service: GithubService,
private val query: String
) : PagingSource<Int, Repo>() {
override suspend fun load(params: LoadParams<Int>): LoadResult<Int, Repo> {
val position = params.key ?: GITHUB_STARTING_PAGE_INDEX
val apiQuery = query + IN_QUALIFIER
return try {
val response = service.searchRepos(apiQuery, position, params.loadSize)
val repos = response.items
val nextKey = if (repos.isEmpty()) {
null
} else {
// initial load size = 3 * NETWORK_PAGE_SIZE
// ensure we're not requesting duplicating items, at the 2nd request
position + (params.loadSize / NETWORK_PAGE_SIZE)
}
val prevKey = if (position == GITHUB_STARTING_PAGE_INDEX) null else position - 1
LoadResult.Page(
data = repos,
prevKey = prevKey,
nextKey = nextKey
)
} catch (exception: IOException) {
LoadResult.Error(exception)
} catch (exception: HttpException) {
LoadResult.Error(exception)
}
}
// The refresh key is used for the initial load of the next PagingSource, after invalidation
override fun getRefreshKey(state: PagingState<Int, Repo>): Int? {
// We need to get the previous key (or next key if previous is null) of the page
// that was closest to the most recently accessed index.
// Anchor position is the most recently accessed index
return state.anchorPosition?.let { anchorPosition ->
state.closestPageToPosition(anchorPosition)?.prevKey?.plus(1)
?: state.closestPageToPosition(anchorPosition)?.nextKey?.minus(1)
}
}
}직접 구현하는 PagingSource는 라이브러리에서 제공되는 추상클래스인 PagingSource를 상속받아, load(), getRefreshKey()를 구현해야 한다. 코드 정의를 따라가 살펴보면 각각은 다음과 같이 선언되어 있다.
public abstract class PagingSource<Key : Any, Value : Any>
public abstract suspend fun load(params: LoadParams<Key>): LoadResult<Key, Value>
public abstract fun getRefreshKey(state: PagingState<Key, Value>): Key?PagingSource는 Pager에 의해 컨트롤 되는데, 데이터를 로드해야하는 경우 load()가 불리고, adapter.refresh()등으로 데이터를 다시 로드해야할 때, 현재 보고 있는 위치의 페이지를 로드하기위해 getRefreshKey()가 불린다.
먼저, load()를 살펴보면 LoadParam<Key> 와 LoadResult<Key, Value>가 생소할 것이다. LoadParam은 구현을 따라가보면, sealed class로 정의되어 있고, 이를 상속한 이너 클래스로 LoadParam.Refresh, LoadParam.Append, LoadParam.Prepend 가 정의되어 있다. 바로 enum 형태의 sealed class 사용패턴이다. 필요시 load() 내에서 LoadParam이 셋중에 어떤 클래스인지 구별하면 로딩상태에 따라 처리가 가능하다.
LoadParams의 속성으로 loadsize가 사용되고 있는데, 이 값은 PagingConfig에 넘겨주는 pageSize의 영향을 받는다. PagingConfig에는 initialLoadingSize속성이 있는데, pageSize * DEFAULT_INITIAL_PAGE_MULTIPLIER 로 기본값이 설정되어 있다. DEFAULT_INITIAL_PAGE_MULTIPLIER = 3으로 정의되어 있어서 최초 로딩시, 그러니까 Prepend에서는 pageSize*3 이 LoadingParams.loadsize로 넘어온다. 처음 이 후, Append시에는 pageSize와 동일하여 처음에만 3페이지를 읽어오게 된다.
LoadResult<Key, Value>는 load()의 리턴값인데, 구현을 살펴보면, 역시 sealed class로 LoadResult.Page 와 LoadResult.Error 의 두 클래스가 상속받는다. 각각, load()의 성공시 리턴값과 실패시 리턴되는 에러값이다. LoadResult.Page의 생성자를 보면, 가져온 데이터의 리스트와 이전 페이지값, 다음페이지값이 들어간다.
이제 예제 코드인 GithubPagingSource로 돌아가보면, 생성자로 받는 service는 github에게 요청을 날리는 retrofit 서비스이고 query는 UI로 받은 검색어이다. retrofit 서비스를 이용하여 데이터를 받아오고 에러가 발생하면 LoadResult.Error를 리턴한다. 에러없이 성공하면, prevKey값과 nextKey값을 계산해서 데이터와 함께 LoadResult.Page를 채워 이것을 리턴해준다.
다음으로 살펴볼 것은 getRefreshKey()인데, 여러 조건들에의해 현재 보고있는 리스트를 새로 읽어들이는 경우에 사용된다. 인자로 PagingState<Key: Any, Value: Any>가 넘어오는데, 여기에는 현재 사용중인 Paging의 여러 정보들이 들어있다. 구현을 따라가보면, 사용중인 page들의 리스트가 들어있으며, 가장 최근에 사용한 아이템의 위치가 anchorPosition에 들어있다. 이 외에도 PagingConfig값이 그대로 들어가 있기도 하다.
리턴값으로는 Key값을 돌려주게 되어 있는데, 예제코드에선 anchorPosition을 기준으로 현재 페이지값을 돌려주고 있다. 현재 페이지를 계산하기 위해, closestPageToPosition()메소드를 이용하고 있으며, 이 메소드의 리턴값이 LoadResult.Page이기 때문에, prevKey와 nextKey중에 존재하는 값을 가지고 1을 더하거나 빼서 현재페이지 값을 돌려주고 있다.
RemoteMediator 의 구현
초반의 라이브러리 구조에서 언급했던 부분인데, 네트워크에서 데이터를 읽어와서 DB에 캐싱하고 앱은 DB에서 데이터를 읽어가는 구조를 권장하고 있다. 여기에서 네트워크와 DB의 연결지점에 RemoteMediator 가 존재한다.
어… 이 부분도 정리를 하긴 해야하는데, 뒤로 미루도록 하겠다. 그렇게 어려운 부분은 아니고, PagingSource의 구현과 유사한 부분이 많다. 제대로 알고싶으면, 앞의 예제에서 사용한 구글 코드랩 AndroidPaging의 13단계부터 보면 될 것이다.
사족…
‘간단하게’ 정리하고 넘어가자고 시작한건데, 생각보다 오래걸렸다. 그래서 나중엔 지쳐버려서 RemoteMediator 부분은 누락시키기도 했다. 이해했다고 생각하고 글을 시작했는데, 막상 시작하고보니 모르는게 많았고, 안드로이드 스튜디오를 이용하면 각 부분들의 구현을 다 들여다 볼 수 있었는데, 처음에는 볼 생각을 안했다. 처음부터 들여다보고 내부구조를 좀 분석해서 그 내용을 올렸으면 어땠을까하는 아쉬움도 생긴다.
나로서는 이거 쓰면서 많이 공부가 됐는데, 다른분들에겐 그닥 도움이 안될거 같기도 하다. 이 블로그 시작이 내가 나중에 찾아볼 수 있는걸 쓰자, 나만 알아보는걸 최소한의 조건으로 걸었는데 알람관련 글이 다른분들에게 도움이 되고 있는걸 보니 욕심을 좀 부렸던거 같다. 아쉽지만 이정도 수준이 내가 원하는 레벨이고, 누군가에게 도움까지 되는글은 나중을 기약해야겠다.